Week-06 (NN with Keras and Hyperparameter Tuning with Keras-Tuner)
Pada modul kali ini kita akan mempelajari lebih lanjut implementasi Neural Network menggunakan Keras API serta cara melakukan hyperparameter tuning menggunakan library Keras-Tuner.
Penjelasan modul serta code pada modul ini akan dibahas lengkap pada sesi praktikum. Penjelasan pada notebook ini hanyalah ringkasan singkat.
Prerequisites
! pip install keras- tunerimport tensorflow as tfimport keras_tuner as ktfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.datasets import fetch_california_housingimport matplotlib.pyplot as plt
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting keras-tuner
Downloading keras_tuner-1.3.5-py3-none-any.whl (176 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 176.1/176.1 kB 7.5 MB/s eta 0:00:00
Requirement already satisfied: packaging in /usr/local/lib/python3.10/dist-packages (from keras-tuner) (23.1)
Requirement already satisfied: requests in /usr/local/lib/python3.10/dist-packages (from keras-tuner) (2.27.1)
Collecting kt-legacy
Downloading kt_legacy-1.0.5-py3-none-any.whl (9.6 kB)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests->keras-tuner) (3.4)
Requirement already satisfied: charset-normalizer~=2.0.0 in /usr/local/lib/python3.10/dist-packages (from requests->keras-tuner) (2.0.12)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests->keras-tuner) (1.26.15)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests->keras-tuner) (2022.12.7)
Installing collected packages: kt-legacy, keras-tuner
Successfully installed keras-tuner-1.3.5 kt-legacy-1.0.5
Build Image Classifier with Sequential API
Keras memiliki tiga macam API yang dapat digunakan, yaitu Sequential, Functional, dan Subclassing. Ketiganya memiliki kelebihan dan kekurangan masing-masing, terutama di sisi kemudahan dan fleksibilitas.
Sequential API merupakan API yang sangat mudah dipahami bagi semua orang yang ingin mempelajari deep learning, tetapi Sequential tidak cukup fleksibel dalam membuat arsitektur model tingkat lanjut karena sifatnya yang mengharuskan tiap layer terhubung satu sama lain dari input hingga output.
Functional API merupakan API yang juga cukup mudah dipahami (sedikit lebih kompleks dibandingkan Sequential), tetapi cukup fleksibel dalam mengimplementasikan beragam arsitektur model.
Subclassing API merupakan API yang cukup sulit dipahami bagi orang yang baru ingin mempelajari deep learning, tetapi di sisi lain API ini merupakan API terfleksibel pada Keras.
Pada modul ini, hanya akan dibahas Sequential dan Functional API.
Pertama, kita akan membuat dua macam model untuk mengklasifikasikan gambar fashion (computer vision). Pertama, kita akan membuat model ANN yang cukup simple, kemudian kita coba model CNN untuk meningkatkan akurasi.
Data Preparation
https://keras.io/api/datasets/fashion_mnist/
= tf.keras.datasets.fashion_mnist= fashion_mnist.load_data()
print (f'X_train_full shape: { X_train_full. shape} ' )print (f'y_train_full shape: { y_train_full. shape} ' )print (f'X_test shape: { X_test. shape} ' )print (f'y_test shape: { y_test. shape} ' )
X_train_full shape: (60000, 28, 28)
y_train_full shape: (60000,)
X_test shape: (10000, 28, 28)
y_test shape: (10000,)
= train_test_split(X_train_full, y_train_full, = 1 / 6 , = 42 )print (f'X_train shape: { X_train. shape} ' )print (f'y_train shape: { y_train. shape} ' )print (f'X_val shape: { X_val. shape} ' )print (f'y_val shape: { y_val. shape} ' )print (f'X_test shape: { X_test. shape} ' )print (f'y_test shape: { y_test. shape} ' )
X_train shape: (50000, 28, 28)
y_train shape: (50000,)
X_val shape: (10000, 28, 28)
y_val shape: (10000,)
X_test shape: (10000, 28, 28)
y_test shape: (10000,)
= X_train / 255 = X_val / 255 = X_test / 255
= ["T-shirt/top" , "Trouser" , "Pullover" , "Dress" , "Coat" ,"Sandal" , "Shirt" , "Sneaker" , "Bag" , "Ankle boot" ]
#@title Slider to look for some image examples {run: "auto"} = 21402 #@param {type:"slider", min:0, max:49999, step:1} = 'gray' )'OFF' )
Simple ANN
Without callbacks
= tf.keras.Sequential([= (28 ,28 )),100 , activation= 'relu' ),50 , activation= 'relu' ),10 , activation= 'softmax' )= tf.keras.optimizers.Adam(learning_rate= 1e-3 )compile (optimizer= opt, loss= 'sparse_categorical_crossentropy' ,= ['accuracy' ])
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
dense (Dense) (None, 100) 78500
dense_1 (Dense) (None, 50) 5050
dense_2 (Dense) (None, 10) 510
=================================================================
Total params: 84,060
Trainable params: 84,060
Non-trainable params: 0
_________________________________________________________________
= model_ann_class.get_weights()
print (type (init_ann_class_weights))print (len (init_ann_class_weights))print (f'First dense w: { init_ann_class_weights[0 ]. shape} ' )print (f'First dense b: { init_ann_class_weights[1 ]. shape} ' )print (f'Second dense w: { init_ann_class_weights[2 ]. shape} ' )print (f'Second dense b: { init_ann_class_weights[3 ]. shape} ' )print (f'Last dense w: { init_ann_class_weights[4 ]. shape} ' )print (f'Last dense b: { init_ann_class_weights[5 ]. shape} ' )
<class 'list'>
6
First dense w: (784, 100)
First dense b: (100,)
Second dense w: (100, 50)
Second dense b: (50,)
Last dense w: (50, 10)
Last dense b: (10,)
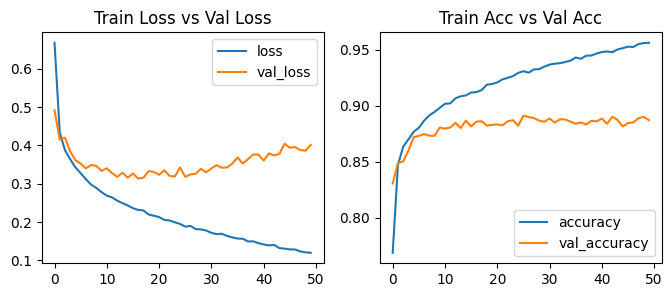
= model_ann_class.fit(X_train, y_train, = (X_val, y_val),= 50 , batch_size= 256 )
Epoch 1/50
196/196 [==============================] - 2s 9ms/step - loss: 0.6681 - accuracy: 0.7688 - val_loss: 0.4915 - val_accuracy: 0.8307
Epoch 2/50
196/196 [==============================] - 2s 11ms/step - loss: 0.4334 - accuracy: 0.8471 - val_loss: 0.4150 - val_accuracy: 0.8491
Epoch 3/50
196/196 [==============================] - 1s 7ms/step - loss: 0.3873 - accuracy: 0.8635 - val_loss: 0.4204 - val_accuracy: 0.8503
Epoch 4/50
196/196 [==============================] - 1s 7ms/step - loss: 0.3637 - accuracy: 0.8700 - val_loss: 0.3839 - val_accuracy: 0.8600
Epoch 5/50
196/196 [==============================] - 1s 7ms/step - loss: 0.3422 - accuracy: 0.8768 - val_loss: 0.3612 - val_accuracy: 0.8720
Epoch 6/50
196/196 [==============================] - 1s 7ms/step - loss: 0.3275 - accuracy: 0.8805 - val_loss: 0.3525 - val_accuracy: 0.8732
Epoch 7/50
196/196 [==============================] - 1s 8ms/step - loss: 0.3116 - accuracy: 0.8868 - val_loss: 0.3400 - val_accuracy: 0.8747
Epoch 8/50
196/196 [==============================] - 1s 8ms/step - loss: 0.2974 - accuracy: 0.8914 - val_loss: 0.3488 - val_accuracy: 0.8734
Epoch 9/50
196/196 [==============================] - 1s 7ms/step - loss: 0.2889 - accuracy: 0.8946 - val_loss: 0.3463 - val_accuracy: 0.8732
Epoch 10/50
196/196 [==============================] - 2s 11ms/step - loss: 0.2777 - accuracy: 0.8982 - val_loss: 0.3333 - val_accuracy: 0.8806
Epoch 11/50
196/196 [==============================] - 2s 9ms/step - loss: 0.2688 - accuracy: 0.9019 - val_loss: 0.3402 - val_accuracy: 0.8796
Epoch 12/50
196/196 [==============================] - 1s 7ms/step - loss: 0.2641 - accuracy: 0.9022 - val_loss: 0.3277 - val_accuracy: 0.8807
Epoch 13/50
196/196 [==============================] - 1s 7ms/step - loss: 0.2556 - accuracy: 0.9067 - val_loss: 0.3177 - val_accuracy: 0.8848
Epoch 14/50
196/196 [==============================] - 1s 7ms/step - loss: 0.2491 - accuracy: 0.9085 - val_loss: 0.3287 - val_accuracy: 0.8802
Epoch 15/50
196/196 [==============================] - 1s 7ms/step - loss: 0.2431 - accuracy: 0.9093 - val_loss: 0.3156 - val_accuracy: 0.8868
Epoch 16/50
196/196 [==============================] - 1s 7ms/step - loss: 0.2358 - accuracy: 0.9119 - val_loss: 0.3266 - val_accuracy: 0.8816
Epoch 17/50
196/196 [==============================] - 1s 7ms/step - loss: 0.2314 - accuracy: 0.9122 - val_loss: 0.3132 - val_accuracy: 0.8859
Epoch 18/50
196/196 [==============================] - 2s 8ms/step - loss: 0.2301 - accuracy: 0.9140 - val_loss: 0.3155 - val_accuracy: 0.8863
Epoch 19/50
196/196 [==============================] - 2s 11ms/step - loss: 0.2193 - accuracy: 0.9189 - val_loss: 0.3328 - val_accuracy: 0.8824
Epoch 20/50
196/196 [==============================] - 2s 8ms/step - loss: 0.2162 - accuracy: 0.9195 - val_loss: 0.3306 - val_accuracy: 0.8830
Epoch 21/50
196/196 [==============================] - 1s 7ms/step - loss: 0.2128 - accuracy: 0.9209 - val_loss: 0.3230 - val_accuracy: 0.8834
Epoch 22/50
196/196 [==============================] - 1s 7ms/step - loss: 0.2053 - accuracy: 0.9236 - val_loss: 0.3350 - val_accuracy: 0.8826
Epoch 23/50
196/196 [==============================] - 1s 7ms/step - loss: 0.2038 - accuracy: 0.9250 - val_loss: 0.3202 - val_accuracy: 0.8862
Epoch 24/50
196/196 [==============================] - 1s 7ms/step - loss: 0.1991 - accuracy: 0.9265 - val_loss: 0.3187 - val_accuracy: 0.8872
Epoch 25/50
196/196 [==============================] - 1s 7ms/step - loss: 0.1948 - accuracy: 0.9294 - val_loss: 0.3424 - val_accuracy: 0.8823
Epoch 26/50
196/196 [==============================] - 1s 7ms/step - loss: 0.1878 - accuracy: 0.9309 - val_loss: 0.3179 - val_accuracy: 0.8912
Epoch 27/50
196/196 [==============================] - 2s 9ms/step - loss: 0.1896 - accuracy: 0.9296 - val_loss: 0.3243 - val_accuracy: 0.8900
Epoch 28/50
196/196 [==============================] - 2s 11ms/step - loss: 0.1812 - accuracy: 0.9325 - val_loss: 0.3260 - val_accuracy: 0.8891
Epoch 29/50
196/196 [==============================] - 1s 7ms/step - loss: 0.1805 - accuracy: 0.9327 - val_loss: 0.3389 - val_accuracy: 0.8868
Epoch 30/50
196/196 [==============================] - 1s 7ms/step - loss: 0.1777 - accuracy: 0.9350 - val_loss: 0.3296 - val_accuracy: 0.8858
Epoch 31/50
196/196 [==============================] - 1s 7ms/step - loss: 0.1716 - accuracy: 0.9368 - val_loss: 0.3398 - val_accuracy: 0.8887
Epoch 32/50
196/196 [==============================] - 1s 7ms/step - loss: 0.1683 - accuracy: 0.9377 - val_loss: 0.3484 - val_accuracy: 0.8850
Epoch 33/50
196/196 [==============================] - 1s 7ms/step - loss: 0.1690 - accuracy: 0.9381 - val_loss: 0.3416 - val_accuracy: 0.8880
Epoch 34/50
196/196 [==============================] - 1s 7ms/step - loss: 0.1635 - accuracy: 0.9391 - val_loss: 0.3423 - val_accuracy: 0.8878
Epoch 35/50
196/196 [==============================] - 1s 7ms/step - loss: 0.1596 - accuracy: 0.9404 - val_loss: 0.3524 - val_accuracy: 0.8859
Epoch 36/50
196/196 [==============================] - 2s 11ms/step - loss: 0.1566 - accuracy: 0.9432 - val_loss: 0.3687 - val_accuracy: 0.8840
Epoch 37/50
196/196 [==============================] - 2s 9ms/step - loss: 0.1561 - accuracy: 0.9420 - val_loss: 0.3525 - val_accuracy: 0.8852
Epoch 38/50
196/196 [==============================] - 1s 7ms/step - loss: 0.1491 - accuracy: 0.9448 - val_loss: 0.3640 - val_accuracy: 0.8833
Epoch 39/50
196/196 [==============================] - 1s 7ms/step - loss: 0.1494 - accuracy: 0.9449 - val_loss: 0.3761 - val_accuracy: 0.8867
Epoch 40/50
196/196 [==============================] - 1s 7ms/step - loss: 0.1446 - accuracy: 0.9467 - val_loss: 0.3758 - val_accuracy: 0.8861
Epoch 41/50
196/196 [==============================] - 1s 7ms/step - loss: 0.1411 - accuracy: 0.9481 - val_loss: 0.3604 - val_accuracy: 0.8886
Epoch 42/50
196/196 [==============================] - 2s 9ms/step - loss: 0.1388 - accuracy: 0.9485 - val_loss: 0.3790 - val_accuracy: 0.8840
Epoch 43/50
196/196 [==============================] - 2s 10ms/step - loss: 0.1399 - accuracy: 0.9479 - val_loss: 0.3736 - val_accuracy: 0.8903
Epoch 44/50
196/196 [==============================] - 3s 15ms/step - loss: 0.1316 - accuracy: 0.9503 - val_loss: 0.3778 - val_accuracy: 0.8874
Epoch 45/50
196/196 [==============================] - 3s 14ms/step - loss: 0.1304 - accuracy: 0.9515 - val_loss: 0.4043 - val_accuracy: 0.8816
Epoch 46/50
196/196 [==============================] - 2s 12ms/step - loss: 0.1283 - accuracy: 0.9528 - val_loss: 0.3941 - val_accuracy: 0.8846
Epoch 47/50
196/196 [==============================] - 2s 13ms/step - loss: 0.1280 - accuracy: 0.9525 - val_loss: 0.3956 - val_accuracy: 0.8851
Epoch 48/50
196/196 [==============================] - 2s 10ms/step - loss: 0.1231 - accuracy: 0.9551 - val_loss: 0.3878 - val_accuracy: 0.8890
Epoch 49/50
196/196 [==============================] - 2s 12ms/step - loss: 0.1206 - accuracy: 0.9560 - val_loss: 0.3860 - val_accuracy: 0.8901
Epoch 50/50
196/196 [==============================] - 3s 17ms/step - loss: 0.1195 - accuracy: 0.9563 - val_loss: 0.4013 - val_accuracy: 0.8872
= history_ann_class.history['loss' ]= history_ann_class.history['val_loss' ]= history_ann_class.history['accuracy' ]= history_ann_class.history['val_accuracy' ]= range (len (loss))= plt.subplots(1 , 2 , figsize= (8 ,3 ))0 ].plot(epochs, loss)0 ].plot(epochs, val_loss)0 ].legend(['loss' , 'val_loss' ], loc= 'upper right' )0 ].set_title('Train Loss vs Val Loss' )1 ].plot(epochs, accuracy)1 ].plot(epochs, val_accuracy)1 ].legend(['accuracy' , 'val_accuracy' ], loc= 'lower right' )1 ].set_title('Train Acc vs Val Acc' )
313/313 [==============================] - 1s 4ms/step - loss: 0.4013 - accuracy: 0.8872
[0.4012959599494934, 0.8871999979019165]
313/313 [==============================] - 1s 4ms/step - loss: 0.4228 - accuracy: 0.8853
[0.42284178733825684, 0.8852999806404114]
With callbacks
313/313 [==============================] - 1s 2ms/step - loss: 2.4112 - accuracy: 0.0420
[2.41121768951416, 0.041999999433755875]
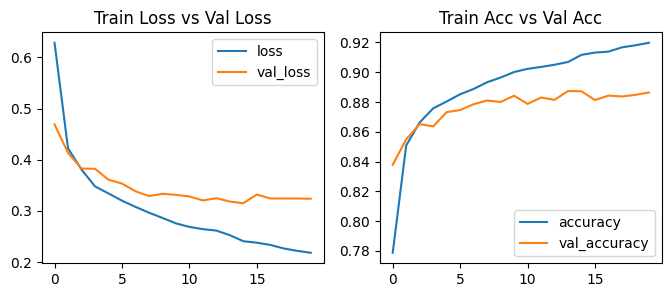
= tf.keras.callbacks.EarlyStopping(patience= 5 , monitor= 'val_loss' ,= True ,= 1 )= model_ann_class.fit(X_train, y_train, = (X_val, y_val),= 50 , batch_size= 256 ,= [early_stop])
Epoch 1/50
196/196 [==============================] - 1s 7ms/step - loss: 0.6287 - accuracy: 0.7787 - val_loss: 0.4691 - val_accuracy: 0.8378
Epoch 2/50
196/196 [==============================] - 1s 7ms/step - loss: 0.4224 - accuracy: 0.8508 - val_loss: 0.4133 - val_accuracy: 0.8549
Epoch 3/50
196/196 [==============================] - 1s 7ms/step - loss: 0.3808 - accuracy: 0.8663 - val_loss: 0.3827 - val_accuracy: 0.8651
Epoch 4/50
196/196 [==============================] - 1s 7ms/step - loss: 0.3479 - accuracy: 0.8757 - val_loss: 0.3823 - val_accuracy: 0.8636
Epoch 5/50
196/196 [==============================] - 2s 9ms/step - loss: 0.3341 - accuracy: 0.8803 - val_loss: 0.3610 - val_accuracy: 0.8732
Epoch 6/50
196/196 [==============================] - 2s 11ms/step - loss: 0.3199 - accuracy: 0.8852 - val_loss: 0.3534 - val_accuracy: 0.8746
Epoch 7/50
196/196 [==============================] - 1s 7ms/step - loss: 0.3079 - accuracy: 0.8888 - val_loss: 0.3383 - val_accuracy: 0.8785
Epoch 8/50
196/196 [==============================] - 1s 7ms/step - loss: 0.2965 - accuracy: 0.8933 - val_loss: 0.3290 - val_accuracy: 0.8810
Epoch 9/50
196/196 [==============================] - 1s 7ms/step - loss: 0.2862 - accuracy: 0.8964 - val_loss: 0.3333 - val_accuracy: 0.8800
Epoch 10/50
196/196 [==============================] - 1s 7ms/step - loss: 0.2756 - accuracy: 0.9001 - val_loss: 0.3313 - val_accuracy: 0.8842
Epoch 11/50
196/196 [==============================] - 1s 7ms/step - loss: 0.2686 - accuracy: 0.9023 - val_loss: 0.3282 - val_accuracy: 0.8787
Epoch 12/50
196/196 [==============================] - 1s 7ms/step - loss: 0.2642 - accuracy: 0.9035 - val_loss: 0.3204 - val_accuracy: 0.8830
Epoch 13/50
196/196 [==============================] - 1s 7ms/step - loss: 0.2615 - accuracy: 0.9050 - val_loss: 0.3247 - val_accuracy: 0.8814
Epoch 14/50
196/196 [==============================] - 2s 10ms/step - loss: 0.2525 - accuracy: 0.9069 - val_loss: 0.3182 - val_accuracy: 0.8874
Epoch 15/50
196/196 [==============================] - 2s 9ms/step - loss: 0.2407 - accuracy: 0.9117 - val_loss: 0.3150 - val_accuracy: 0.8872
Epoch 16/50
196/196 [==============================] - 1s 7ms/step - loss: 0.2378 - accuracy: 0.9132 - val_loss: 0.3320 - val_accuracy: 0.8813
Epoch 17/50
196/196 [==============================] - 1s 7ms/step - loss: 0.2334 - accuracy: 0.9138 - val_loss: 0.3242 - val_accuracy: 0.8843
Epoch 18/50
196/196 [==============================] - 1s 7ms/step - loss: 0.2265 - accuracy: 0.9167 - val_loss: 0.3242 - val_accuracy: 0.8837
Epoch 19/50
196/196 [==============================] - 1s 7ms/step - loss: 0.2218 - accuracy: 0.9181 - val_loss: 0.3242 - val_accuracy: 0.8848
Epoch 20/50
196/196 [==============================] - ETA: 0s - loss: 0.2180 - accuracy: 0.9198Restoring model weights from the end of the best epoch: 15.
196/196 [==============================] - 1s 7ms/step - loss: 0.2180 - accuracy: 0.9198 - val_loss: 0.3237 - val_accuracy: 0.8864
Epoch 20: early stopping
= history_ann_class.history['loss' ]= history_ann_class.history['val_loss' ]= history_ann_class.history['accuracy' ]= history_ann_class.history['val_accuracy' ]= range (len (loss))= plt.subplots(1 , 2 , figsize= (8 ,3 ))0 ].plot(epochs, loss)0 ].plot(epochs, val_loss)0 ].legend(['loss' , 'val_loss' ], loc= 'upper right' )0 ].set_title('Train Loss vs Val Loss' )1 ].plot(epochs, accuracy)1 ].plot(epochs, val_accuracy)1 ].legend(['accuracy' , 'val_accuracy' ], loc= 'lower right' )1 ].set_title('Train Acc vs Val Acc' )
313/313 [==============================] - 1s 4ms/step - loss: 0.3150 - accuracy: 0.8872
[0.31500566005706787, 0.8871999979019165]
313/313 [==============================] - 2s 5ms/step - loss: 0.3424 - accuracy: 0.8841
[0.342407763004303, 0.8841000199317932]
CNN
= tf.keras.Sequential([= 32 , kernel_size= (5 ,5 ),= 'relu' , input_shape= (28 ,28 ,1 )),= 2 ),64 , (3 ,3 ), activation= 'relu' ),2 ),100 , activation= 'relu' ),50 , activation= 'relu' ),10 , activation= 'softmax' )compile (optimizer= 'adam' , loss= 'sparse_categorical_crossentropy' ,= 'accuracy' )
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 24, 24, 32) 832
max_pooling2d (MaxPooling2D (None, 12, 12, 32) 0
)
conv2d_1 (Conv2D) (None, 10, 10, 64) 18496
max_pooling2d_1 (MaxPooling (None, 5, 5, 64) 0
2D)
flatten (Flatten) (None, 1600) 0
dense (Dense) (None, 100) 160100
dense_1 (Dense) (None, 50) 5050
dense_2 (Dense) (None, 10) 510
=================================================================
Total params: 184,988
Trainable params: 184,988
Non-trainable params: 0
_________________________________________________________________
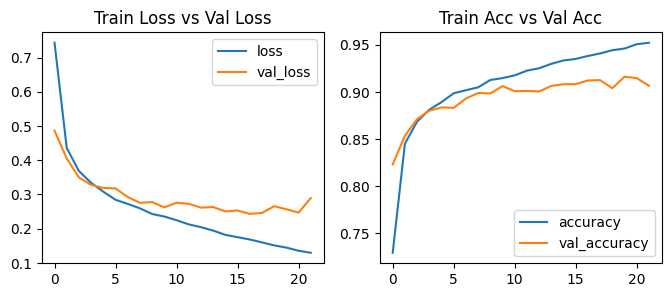
= tf.keras.callbacks.EarlyStopping(patience= 5 , monitor= 'val_loss' ,= True ,= 1 )= model_cnn.fit(X_train, y_train, validation_data= (X_val, y_val),= 100 , batch_size= 256 , = [early_stop])
Epoch 1/100
196/196 [==============================] - 4s 9ms/step - loss: 0.7431 - accuracy: 0.7296 - val_loss: 0.4864 - val_accuracy: 0.8231
Epoch 2/100
196/196 [==============================] - 1s 7ms/step - loss: 0.4358 - accuracy: 0.8453 - val_loss: 0.4050 - val_accuracy: 0.8536
Epoch 3/100
196/196 [==============================] - 1s 7ms/step - loss: 0.3686 - accuracy: 0.8686 - val_loss: 0.3497 - val_accuracy: 0.8712
Epoch 4/100
196/196 [==============================] - 1s 6ms/step - loss: 0.3341 - accuracy: 0.8812 - val_loss: 0.3283 - val_accuracy: 0.8801
Epoch 5/100
196/196 [==============================] - 1s 6ms/step - loss: 0.3081 - accuracy: 0.8892 - val_loss: 0.3191 - val_accuracy: 0.8836
Epoch 6/100
196/196 [==============================] - 1s 6ms/step - loss: 0.2845 - accuracy: 0.8986 - val_loss: 0.3178 - val_accuracy: 0.8832
Epoch 7/100
196/196 [==============================] - 1s 6ms/step - loss: 0.2725 - accuracy: 0.9018 - val_loss: 0.2926 - val_accuracy: 0.8930
Epoch 8/100
196/196 [==============================] - 1s 6ms/step - loss: 0.2596 - accuracy: 0.9049 - val_loss: 0.2756 - val_accuracy: 0.8989
Epoch 9/100
196/196 [==============================] - 1s 6ms/step - loss: 0.2430 - accuracy: 0.9127 - val_loss: 0.2777 - val_accuracy: 0.8984
Epoch 10/100
196/196 [==============================] - 1s 6ms/step - loss: 0.2356 - accuracy: 0.9147 - val_loss: 0.2626 - val_accuracy: 0.9062
Epoch 11/100
196/196 [==============================] - 1s 7ms/step - loss: 0.2249 - accuracy: 0.9176 - val_loss: 0.2759 - val_accuracy: 0.9008
Epoch 12/100
196/196 [==============================] - 1s 7ms/step - loss: 0.2127 - accuracy: 0.9226 - val_loss: 0.2729 - val_accuracy: 0.9011
Epoch 13/100
196/196 [==============================] - 1s 7ms/step - loss: 0.2046 - accuracy: 0.9251 - val_loss: 0.2617 - val_accuracy: 0.9005
Epoch 14/100
196/196 [==============================] - 1s 6ms/step - loss: 0.1946 - accuracy: 0.9298 - val_loss: 0.2634 - val_accuracy: 0.9064
Epoch 15/100
196/196 [==============================] - 1s 6ms/step - loss: 0.1821 - accuracy: 0.9333 - val_loss: 0.2505 - val_accuracy: 0.9082
Epoch 16/100
196/196 [==============================] - 1s 6ms/step - loss: 0.1754 - accuracy: 0.9350 - val_loss: 0.2533 - val_accuracy: 0.9083
Epoch 17/100
196/196 [==============================] - 1s 6ms/step - loss: 0.1686 - accuracy: 0.9381 - val_loss: 0.2435 - val_accuracy: 0.9122
Epoch 18/100
196/196 [==============================] - 1s 6ms/step - loss: 0.1602 - accuracy: 0.9408 - val_loss: 0.2461 - val_accuracy: 0.9125
Epoch 19/100
196/196 [==============================] - 1s 6ms/step - loss: 0.1513 - accuracy: 0.9442 - val_loss: 0.2658 - val_accuracy: 0.9040
Epoch 20/100
196/196 [==============================] - 1s 6ms/step - loss: 0.1449 - accuracy: 0.9460 - val_loss: 0.2570 - val_accuracy: 0.9161
Epoch 21/100
196/196 [==============================] - 1s 7ms/step - loss: 0.1357 - accuracy: 0.9506 - val_loss: 0.2469 - val_accuracy: 0.9147
Epoch 22/100
194/196 [============================>.] - ETA: 0s - loss: 0.1297 - accuracy: 0.9521Restoring model weights from the end of the best epoch: 17.
196/196 [==============================] - 1s 7ms/step - loss: 0.1298 - accuracy: 0.9521 - val_loss: 0.2894 - val_accuracy: 0.9066
Epoch 22: early stopping
= history_cnn.history['loss' ]= history_cnn.history['val_loss' ]= history_cnn.history['accuracy' ]= history_cnn.history['val_accuracy' ]= range (len (loss))= plt.subplots(1 , 2 , figsize= (8 ,3 ))0 ].plot(epochs, loss)0 ].plot(epochs, val_loss)0 ].legend(['loss' , 'val_loss' ], loc= 'upper right' )0 ].set_title('Train Loss vs Val Loss' )1 ].plot(epochs, accuracy)1 ].plot(epochs, val_accuracy)1 ].legend(['accuracy' , 'val_accuracy' ], loc= 'lower right' )1 ].set_title('Train Acc vs Val Acc' )
313/313 [==============================] - 1s 3ms/step - loss: 0.2435 - accuracy: 0.9122
[0.2434857189655304, 0.9121999740600586]
313/313 [==============================] - 1s 2ms/step - loss: 0.2664 - accuracy: 0.9079
[0.26635172963142395, 0.9078999757766724]
= tf.argmax(model_cnn.predict(X_test), axis=- 1 ).numpy()10 ], y_test[:10 ]
313/313 [==============================] - 1s 2ms/step
(array([9, 2, 1, 1, 6, 1, 4, 6, 5, 7]),
array([9, 2, 1, 1, 6, 1, 4, 6, 5, 7], dtype=uint8))
#@title Wrong Prediction image {run:"auto"} = (y_pred != y_test)= 8 #@param {type:"slider", min:0, max:20, step:1} print (f'Prediction: { class_names[y_pred[wrong_pred][wrong_pred_idx]]} ' )print (f'Truth: { class_names[y_test[wrong_pred][wrong_pred_idx]]} ' )= 'gray' )'OFF' )
Prediction: Coat
Truth: Pullover
Build NN Regressor with Sequential API
Selanjutnya, kita coba untuk membuat model ANN untuk masalah regresi (harga rumah).
Data Preparation
= fetch_california_housing()= housing['data' ]= housing['target' ]print (f'X shape: { X. shape} ' )print (f'y shape: { y. shape} ' )
X shape: (20640, 8)
y shape: (20640,)
= train_test_split(X, y, test_size= .4 ,= 42 )= train_test_split(X_test, y_test, test_size= .5 ,= 42 )print (f'X_train shape: { X_train. shape} ' )print (f'y_train shape: { y_train. shape} ' )print (f'X_val shape: { X_val. shape} ' )print (f'y_val shape: { y_val. shape} ' )print (f'X_test shape: { X_test. shape} ' )print (f'y_test shape: { y_test. shape} ' )
X_train shape: (12384, 8)
y_train shape: (12384,)
X_val shape: (4128, 8)
y_val shape: (4128,)
X_test shape: (4128, 8)
y_test shape: (4128,)
= StandardScaler()= scaler.fit_transform(X_train)= scaler.transform(X_val)= scaler.transform(X_test)
print (f'y min: { y_train. min ()} ' )print (f'y max: { y_train. max ()} ' )
y min: 0.14999
y max: 5.00001
Modelling
= tf.keras.Sequential([30 , activation= 'relu' ,= X_train.shape[1 :]),1 , activation= 'relu' )compile (optimizer= 'adam' , loss= 'mse' )
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 30) 270
dense_1 (Dense) (None, 1) 31
=================================================================
Total params: 301
Trainable params: 301
Non-trainable params: 0
_________________________________________________________________
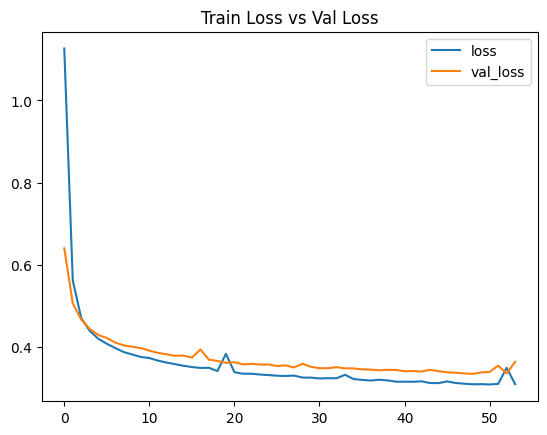
= tf.keras.callbacks.EarlyStopping(patience= 5 , monitor= 'val_loss' ,= True ,= 1 )= model_reg.fit(X_train, y_train, validation_data= (X_val, y_val),= 500 , callbacks= [early_stop])
Epoch 1/500
387/387 [==============================] - 2s 3ms/step - loss: 1.1266 - val_loss: 0.6397
Epoch 2/500
387/387 [==============================] - 1s 3ms/step - loss: 0.5616 - val_loss: 0.5056
Epoch 3/500
387/387 [==============================] - 1s 3ms/step - loss: 0.4695 - val_loss: 0.4661
Epoch 4/500
387/387 [==============================] - 1s 3ms/step - loss: 0.4385 - val_loss: 0.4433
Epoch 5/500
387/387 [==============================] - 1s 3ms/step - loss: 0.4195 - val_loss: 0.4286
Epoch 6/500
387/387 [==============================] - 1s 3ms/step - loss: 0.4072 - val_loss: 0.4212
Epoch 7/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3966 - val_loss: 0.4100
Epoch 8/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3869 - val_loss: 0.4032
Epoch 9/500
387/387 [==============================] - 1s 4ms/step - loss: 0.3810 - val_loss: 0.3999
Epoch 10/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3751 - val_loss: 0.3966
Epoch 11/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3723 - val_loss: 0.3905
Epoch 12/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3662 - val_loss: 0.3851
Epoch 13/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3615 - val_loss: 0.3816
Epoch 14/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3576 - val_loss: 0.3778
Epoch 15/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3537 - val_loss: 0.3785
Epoch 16/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3505 - val_loss: 0.3734
Epoch 17/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3483 - val_loss: 0.3933
Epoch 18/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3487 - val_loss: 0.3685
Epoch 19/500
387/387 [==============================] - 3s 8ms/step - loss: 0.3406 - val_loss: 0.3654
Epoch 20/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3827 - val_loss: 0.3608
Epoch 21/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3379 - val_loss: 0.3623
Epoch 22/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3342 - val_loss: 0.3568
Epoch 23/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3342 - val_loss: 0.3583
Epoch 24/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3322 - val_loss: 0.3565
Epoch 25/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3310 - val_loss: 0.3567
Epoch 26/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3294 - val_loss: 0.3529
Epoch 27/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3287 - val_loss: 0.3545
Epoch 28/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3297 - val_loss: 0.3495
Epoch 29/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3249 - val_loss: 0.3585
Epoch 30/500
387/387 [==============================] - 1s 4ms/step - loss: 0.3247 - val_loss: 0.3511
Epoch 31/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3226 - val_loss: 0.3478
Epoch 32/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3234 - val_loss: 0.3475
Epoch 33/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3231 - val_loss: 0.3502
Epoch 34/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3316 - val_loss: 0.3473
Epoch 35/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3212 - val_loss: 0.3471
Epoch 36/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3192 - val_loss: 0.3448
Epoch 37/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3176 - val_loss: 0.3443
Epoch 38/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3195 - val_loss: 0.3426
Epoch 39/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3180 - val_loss: 0.3437
Epoch 40/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3148 - val_loss: 0.3434
Epoch 41/500
387/387 [==============================] - 1s 4ms/step - loss: 0.3148 - val_loss: 0.3402
Epoch 42/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3146 - val_loss: 0.3408
Epoch 43/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3157 - val_loss: 0.3396
Epoch 44/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3115 - val_loss: 0.3438
Epoch 45/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3114 - val_loss: 0.3403
Epoch 46/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3155 - val_loss: 0.3378
Epoch 47/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3117 - val_loss: 0.3367
Epoch 48/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3099 - val_loss: 0.3349
Epoch 49/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3085 - val_loss: 0.3338
Epoch 50/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3088 - val_loss: 0.3373
Epoch 51/500
387/387 [==============================] - 1s 3ms/step - loss: 0.3080 - val_loss: 0.3387
Epoch 52/500
387/387 [==============================] - 1s 4ms/step - loss: 0.3094 - val_loss: 0.3539
Epoch 53/500
387/387 [==============================] - 2s 6ms/step - loss: 0.3487 - val_loss: 0.3349
Epoch 54/500
373/387 [===========================>..] - ETA: 0s - loss: 0.3093Restoring model weights from the end of the best epoch: 49.
387/387 [==============================] - 2s 6ms/step - loss: 0.3087 - val_loss: 0.3633
Epoch 54: early stopping
= history_reg.history['loss' ]= history_reg.history['val_loss' ]= range (len (loss))'loss' , 'val_loss' ], loc= 'upper right' )'Train Loss vs Val Loss' )
129/129 [==============================] - 1s 3ms/step - loss: 0.3338
129/129 [==============================] - 0s 3ms/step - loss: 0.3242
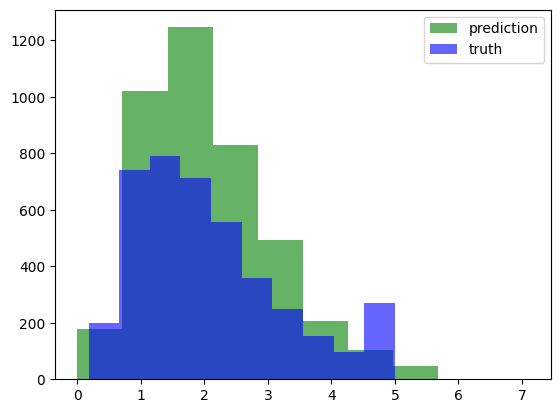
= model_reg.predict(X_test)= 'green' , alpha= .6 )= 'blue' , alpha= .6 )'prediction' , 'truth' ], loc= 'upper right' )
129/129 [==============================] - 0s 3ms/step
Functional API
Berikut merupakan contoh - contoh penggunaan Functional API. Pada modul ini tidak dibahas banyak karena penggunaannya yang cukup mudah, hanya sedikit berbeda dengan Sequential.
Informasi lebih lanjut dapat dipelajari pada link berikut: https://keras.io/guides/functional_api/
Example 1
Membuat NN regressor dengan arsitekur yang sama seperti saat menggunakan Sequential API di atas.
= tf.keras.layers.Input(shape= X_train.shape[1 :])= tf.keras.layers.Dense(30 , activation= 'relu' )(input_layer)= tf.keras.layers.Dense(1 , activation= 'relu' )(dense)= tf.keras.Model(inputs= input_layer, outputs= output_layer)compile (optimizer= 'adam' , loss= 'mse' )
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 8)] 0
dense (Dense) (None, 30) 270
dense_1 (Dense) (None, 1) 31
=================================================================
Total params: 301
Trainable params: 301
Non-trainable params: 0
_________________________________________________________________
Example 2
Membuat arsitektur “Wide & Deep”
Reference: “Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow” by Aurélien Géron
= tf.keras.layers.Input(shape= X_train.shape[1 :])= tf.keras.layers.Dense(30 , activation= "relu" )(input_layer)= tf.keras.layers.Dense(30 , activation= "relu" )(hidden1)= tf.keras.layers.Concatenate()([input_layer, hidden2])= tf.keras.layers.Dense(1 )(concat)= tf.keras.Model(inputs= input_layer, outputs= output,= 'wide_and_deep' )compile (optimizer= 'adam' , loss= 'mse' )
Model: "wide_and_deep"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 8)] 0 []
dense (Dense) (None, 30) 270 ['input_1[0][0]']
dense_1 (Dense) (None, 30) 930 ['dense[0][0]']
concatenate (Concatenate) (None, 38) 0 ['input_1[0][0]',
'dense_1[0][0]']
dense_2 (Dense) (None, 1) 39 ['concatenate[0][0]']
==================================================================================================
Total params: 1,239
Trainable params: 1,239
Non-trainable params: 0
__________________________________________________________________________________________________
Example 3
Membuat arsitektur dengan multiple input
Reference: “Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow” by Aurélien Géron
= tf.keras.layers.Input(shape= [5 ], name= "wide_input" )= tf.keras.layers.Input(shape= [6 ], name= "deep_input" )= tf.keras.layers.Dense(30 , activation= "relu" )(input_B)= tf.keras.layers.Dense(30 , activation= "relu" )(hidden1)= tf.keras.layers.concatenate([input_A, hidden2])= tf.keras.layers.Dense(1 , name= "output" )(concat)= tf.keras.Model(inputs= [input_A, input_B], outputs= [output],= 'multiple_input' )compile (optimizer= 'adam' , loss= 'mse' )
Model: "multiple_input"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
deep_input (InputLayer) [(None, 6)] 0 []
dense (Dense) (None, 30) 210 ['deep_input[0][0]']
wide_input (InputLayer) [(None, 5)] 0 []
dense_1 (Dense) (None, 30) 930 ['dense[0][0]']
concatenate (Concatenate) (None, 35) 0 ['wide_input[0][0]',
'dense_1[0][0]']
output (Dense) (None, 1) 36 ['concatenate[0][0]']
==================================================================================================
Total params: 1,176
Trainable params: 1,176
Non-trainable params: 0
__________________________________________________________________________________________________
Hyperparameter Tuning with Keras-Tuner
Pada bagian terakhir dari modul ini, kita akan mencoba melakukan hyperparameter tuning untuk menentukan arsitektur NN terbaik yang menghasilkan val_loss terendah.
Informasi lebih lanjut dapat dilihat pada dokumentasi keras-tuner: https://keras.io/api/keras_tuner/
def build_model_reg(hp):= tf.keras.Sequential()= hp.Int('n_hid_layers' , 1 , 2 )for layer in range (n_hid_layers):= hp.Int(f'n_neurons_ { layer} ' , 32 , 128 , step= 16 )= hp.Choice(f'activation_ { layer} ' , 'relu' , 'linear' , 'sigmoid' ])= act))= hp.Choice('activation_output' , ['relu' , 'linear' ])1 , activation= act_output))= hp.Float('learning_rate' , 1e-5 , 1e-2 )= tf.keras.optimizers.Adam(learning_rate= lr)compile (optimizer= opt, loss= 'mse' )return model
Tuning Process
= kt.BayesianOptimization(hypermodel= build_model_reg,= 'val_loss' ,= 10 ,= 'tuner_dir_0' ,= 'tune_housing_model' )
Search space summary
Default search space size: 5
n_hid_layers (Int)
{'default': None, 'conditions': [], 'min_value': 1, 'max_value': 2, 'step': 1, 'sampling': 'linear'}
n_neurons_0 (Int)
{'default': None, 'conditions': [], 'min_value': 32, 'max_value': 128, 'step': 16, 'sampling': 'linear'}
activation_0 (Choice)
{'default': 'relu', 'conditions': [], 'values': ['relu', 'linear', 'sigmoid'], 'ordered': False}
activation_output (Choice)
{'default': 'relu', 'conditions': [], 'values': ['relu', 'linear'], 'ordered': False}
learning_rate (Float)
{'default': 1e-05, 'conditions': [], 'min_value': 1e-05, 'max_value': 0.01, 'step': None, 'sampling': 'linear'}
= (X_val, y_val),= 100 , batch_size= 256 )
Trial 10 Complete [00h 00m 42s]
val_loss: 0.27770957350730896
Best val_loss So Far: 0.27770957350730896
Total elapsed time: 00h 06m 40s
Results summary
Results in tuner_dir_0/tune_housing_model
Showing 3 best trials
Objective(name="val_loss", direction="min")
Trial 09 summary
Hyperparameters:
n_hid_layers: 2
n_neurons_0: 48
activation_0: relu
activation_output: linear
learning_rate: 0.00724696590440984
n_neurons_1: 96
activation_1: sigmoid
Score: 0.27770957350730896
Trial 01 summary
Hyperparameters:
n_hid_layers: 2
n_neurons_0: 128
activation_0: sigmoid
activation_output: linear
learning_rate: 0.009038408225650444
n_neurons_1: 64
activation_1: relu
Score: 0.28969764709472656
Trial 02 summary
Hyperparameters:
n_hid_layers: 1
n_neurons_0: 80
activation_0: relu
activation_output: linear
learning_rate: 0.004831622738137635
n_neurons_1: 32
activation_1: relu
Score: 0.3006684482097626
Retrain best model
= build_model_reg(tuner.get_best_hyperparameters()[0 ])= (None ,) + X_train.shape[1 :])
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_6 (Dense) (None, 48) 432
dense_7 (Dense) (None, 96) 4704
dense_8 (Dense) (None, 1) 97
=================================================================
Total params: 5,233
Trainable params: 5,233
Non-trainable params: 0
_________________________________________________________________
= tf.keras.callbacks.EarlyStopping(patience= 10 , monitor= 'val_loss' ,= True ,= 1 )= model.fit(X_train, y_train, validation_data= (X_val, y_val),= 500 , batch_size= 256 , callbacks= [early_stop])
Epoch 1/500
49/49 [==============================] - 3s 11ms/step - loss: 1.1235 - val_loss: 0.5184
Epoch 2/500
49/49 [==============================] - 0s 7ms/step - loss: 0.4471 - val_loss: 0.4324
Epoch 3/500
49/49 [==============================] - 0s 6ms/step - loss: 0.3967 - val_loss: 0.4041
Epoch 4/500
49/49 [==============================] - 0s 7ms/step - loss: 0.3720 - val_loss: 0.3898
Epoch 5/500
49/49 [==============================] - 0s 7ms/step - loss: 0.3610 - val_loss: 0.3772
Epoch 6/500
49/49 [==============================] - 0s 6ms/step - loss: 0.3529 - val_loss: 0.3724
Epoch 7/500
49/49 [==============================] - 0s 7ms/step - loss: 0.3494 - val_loss: 0.3672
Epoch 8/500
49/49 [==============================] - 0s 6ms/step - loss: 0.3378 - val_loss: 0.3561
Epoch 9/500
49/49 [==============================] - 0s 5ms/step - loss: 0.3316 - val_loss: 0.3472
Epoch 10/500
49/49 [==============================] - 0s 4ms/step - loss: 0.3279 - val_loss: 0.3419
Epoch 11/500
49/49 [==============================] - 0s 4ms/step - loss: 0.3230 - val_loss: 0.3534
Epoch 12/500
49/49 [==============================] - 0s 4ms/step - loss: 0.3173 - val_loss: 0.3345
Epoch 13/500
49/49 [==============================] - 0s 4ms/step - loss: 0.3128 - val_loss: 0.3340
Epoch 14/500
49/49 [==============================] - 0s 4ms/step - loss: 0.3110 - val_loss: 0.3310
Epoch 15/500
49/49 [==============================] - 0s 4ms/step - loss: 0.3042 - val_loss: 0.3332
Epoch 16/500
49/49 [==============================] - 0s 4ms/step - loss: 0.3041 - val_loss: 0.3248
Epoch 17/500
49/49 [==============================] - 0s 6ms/step - loss: 0.2975 - val_loss: 0.3290
Epoch 18/500
49/49 [==============================] - 0s 6ms/step - loss: 0.2991 - val_loss: 0.3225
Epoch 19/500
49/49 [==============================] - 0s 6ms/step - loss: 0.2929 - val_loss: 0.3183
Epoch 20/500
49/49 [==============================] - 0s 6ms/step - loss: 0.2927 - val_loss: 0.3366
Epoch 21/500
49/49 [==============================] - 0s 6ms/step - loss: 0.2909 - val_loss: 0.3194
Epoch 22/500
49/49 [==============================] - 0s 6ms/step - loss: 0.2889 - val_loss: 0.3159
Epoch 23/500
49/49 [==============================] - 0s 6ms/step - loss: 0.2871 - val_loss: 0.3114
Epoch 24/500
49/49 [==============================] - 0s 6ms/step - loss: 0.2891 - val_loss: 0.3127
Epoch 25/500
49/49 [==============================] - 0s 6ms/step - loss: 0.2832 - val_loss: 0.3121
Epoch 26/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2845 - val_loss: 0.3264
Epoch 27/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2882 - val_loss: 0.3065
Epoch 28/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2848 - val_loss: 0.3232
Epoch 29/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2855 - val_loss: 0.3053
Epoch 30/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2784 - val_loss: 0.3027
Epoch 31/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2803 - val_loss: 0.3298
Epoch 32/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2765 - val_loss: 0.3051
Epoch 33/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2796 - val_loss: 0.2993
Epoch 34/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2725 - val_loss: 0.3027
Epoch 35/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2790 - val_loss: 0.3162
Epoch 36/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2750 - val_loss: 0.3013
Epoch 37/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2789 - val_loss: 0.3064
Epoch 38/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2705 - val_loss: 0.3062
Epoch 39/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2706 - val_loss: 0.3087
Epoch 40/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2682 - val_loss: 0.2949
Epoch 41/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2649 - val_loss: 0.3018
Epoch 42/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2701 - val_loss: 0.3006
Epoch 43/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2656 - val_loss: 0.2946
Epoch 44/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2641 - val_loss: 0.2970
Epoch 45/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2653 - val_loss: 0.2900
Epoch 46/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2669 - val_loss: 0.3028
Epoch 47/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2659 - val_loss: 0.2936
Epoch 48/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2652 - val_loss: 0.2974
Epoch 49/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2613 - val_loss: 0.3024
Epoch 50/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2626 - val_loss: 0.2932
Epoch 51/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2588 - val_loss: 0.2958
Epoch 52/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2602 - val_loss: 0.2936
Epoch 53/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2630 - val_loss: 0.2977
Epoch 54/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2628 - val_loss: 0.2893
Epoch 55/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2586 - val_loss: 0.2858
Epoch 56/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2569 - val_loss: 0.2890
Epoch 57/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2571 - val_loss: 0.2903
Epoch 58/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2588 - val_loss: 0.2977
Epoch 59/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2559 - val_loss: 0.2848
Epoch 60/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2584 - val_loss: 0.3046
Epoch 61/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2584 - val_loss: 0.3007
Epoch 62/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2556 - val_loss: 0.2972
Epoch 63/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2525 - val_loss: 0.2865
Epoch 64/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2499 - val_loss: 0.2841
Epoch 65/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2519 - val_loss: 0.2842
Epoch 66/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2536 - val_loss: 0.2845
Epoch 67/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2520 - val_loss: 0.2908
Epoch 68/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2526 - val_loss: 0.2809
Epoch 69/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2526 - val_loss: 0.2859
Epoch 70/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2463 - val_loss: 0.2805
Epoch 71/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2456 - val_loss: 0.2853
Epoch 72/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2470 - val_loss: 0.2829
Epoch 73/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2463 - val_loss: 0.2827
Epoch 74/500
49/49 [==============================] - 0s 6ms/step - loss: 0.2457 - val_loss: 0.2794
Epoch 75/500
49/49 [==============================] - 0s 6ms/step - loss: 0.2461 - val_loss: 0.2793
Epoch 76/500
49/49 [==============================] - 0s 6ms/step - loss: 0.2488 - val_loss: 0.2824
Epoch 77/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2412 - val_loss: 0.2795
Epoch 78/500
49/49 [==============================] - 0s 6ms/step - loss: 0.2423 - val_loss: 0.2789
Epoch 79/500
49/49 [==============================] - 0s 6ms/step - loss: 0.2426 - val_loss: 0.2810
Epoch 80/500
49/49 [==============================] - 0s 6ms/step - loss: 0.2424 - val_loss: 0.2805
Epoch 81/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2421 - val_loss: 0.2767
Epoch 82/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2418 - val_loss: 0.2835
Epoch 83/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2454 - val_loss: 0.2826
Epoch 84/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2373 - val_loss: 0.2756
Epoch 85/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2365 - val_loss: 0.2821
Epoch 86/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2386 - val_loss: 0.2828
Epoch 87/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2352 - val_loss: 0.2786
Epoch 88/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2360 - val_loss: 0.2780
Epoch 89/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2327 - val_loss: 0.2793
Epoch 90/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2366 - val_loss: 0.2755
Epoch 91/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2352 - val_loss: 0.2758
Epoch 92/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2334 - val_loss: 0.2770
Epoch 93/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2333 - val_loss: 0.2821
Epoch 94/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2327 - val_loss: 0.2780
Epoch 95/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2323 - val_loss: 0.2752
Epoch 96/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2369 - val_loss: 0.2760
Epoch 97/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2319 - val_loss: 0.2744
Epoch 98/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2313 - val_loss: 0.2806
Epoch 99/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2319 - val_loss: 0.2770
Epoch 100/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2330 - val_loss: 0.2782
Epoch 101/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2287 - val_loss: 0.2793
Epoch 102/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2269 - val_loss: 0.2736
Epoch 103/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2285 - val_loss: 0.2821
Epoch 104/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2273 - val_loss: 0.2753
Epoch 105/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2265 - val_loss: 0.2779
Epoch 106/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2259 - val_loss: 0.2780
Epoch 107/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2267 - val_loss: 0.2743
Epoch 108/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2289 - val_loss: 0.2751
Epoch 109/500
49/49 [==============================] - 0s 5ms/step - loss: 0.2259 - val_loss: 0.2879
Epoch 110/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2296 - val_loss: 0.2814
Epoch 111/500
49/49 [==============================] - 0s 4ms/step - loss: 0.2274 - val_loss: 0.2887
Epoch 112/500
36/49 [=====================>........] - ETA: 0s - loss: 0.2293Restoring model weights from the end of the best epoch: 102.
49/49 [==============================] - 0s 5ms/step - loss: 0.2289 - val_loss: 0.2867
Epoch 112: early stopping
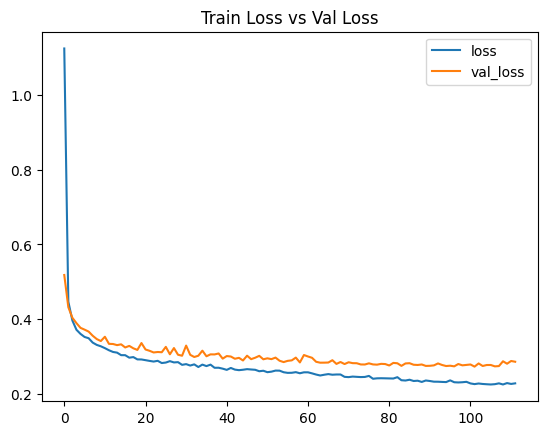
= history.history['loss' ]= history.history['val_loss' ]= range (len (loss))'loss' , 'val_loss' ], loc= 'upper right' )'Train Loss vs Val Loss' )
129/129 [==============================] - 0s 2ms/step - loss: 0.2736
129/129 [==============================] - 0s 3ms/step - loss: 0.2652
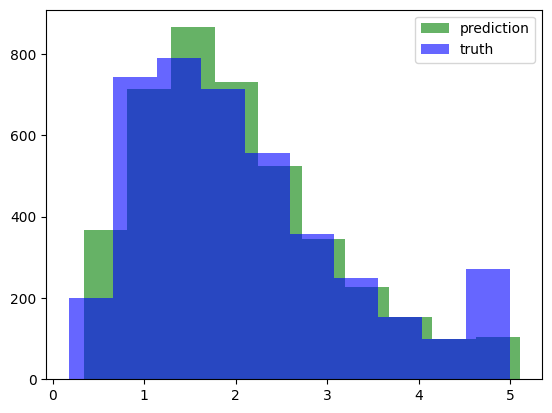
= model.predict(X_test)= 'green' , alpha= .6 )= 'blue' , alpha= .6 )'prediction' , 'truth' ], loc= 'upper right' )
129/129 [==============================] - 0s 1ms/step
Valuable Resources to Learn More:
http://neuralnetworksanddeeplearning.com/ (membahas cara kerja neural network secara matematis, cocok untuk yang suka belajar dengan membaca)
http://introtodeeplearning.com/ (membahas cara kerja neural network hingga CNN, RNN, reinforcement learning, dan lain - lain, cocok untuk yang suka belajar dengan menonton video dan ingin mendalami deep learning lebih lanjut)
Buku “Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow” by Aurélien Géron (membahas implementasi Machine Learning dan Deep Learning pada library-library yang tertera di judulnya)