Training a “Reasoning” Model from an Instruct Model
As the title suggests, I put “Reasoning” in quotes because it’s not really a reasoning model in the sense that it can solve hard math or puzzle problems. I just want to make the model output <reasoning></reasoning> tags before answering. :D
A lot happened over the past two months while working on this, and I want to share my thoughts and experience from the journey.
Background
This work is part of a competition I registered for. The goal was to make a small model output reasoning tags before answering. The model in question is gemma-3-1b-it (yes, this is a Google competition). We needed to build a general reasoner within a 9-hour training window, using the same hardware: TPU v5e-8.
There were no limitations on the techniques or data we could use—everything was as open as it gets.
A starter notebook was provided that uses GRPO to train the model on openai/gsm8k, but this is a specific problem with a clear reward signal (correct or incorrect answer). Our goal was different: we wanted to build a chat model that can reason in general settings.
GRPO (Group Relative Policy Optimization) and RLVR in General
GRPO is the common method used in this competition—not only because of the starter notebook, but also because this method is so popular that any newcomer will have heard of it at least once.
In general, GRPO is a variant of REINFORCE (vanilla policy gradient) with a specific reward computation and a specific normalization scheme.
In vanilla policy gradient, we want to find a policy such that it maximizes:
where is some reward function.
It’s easy to show that:
You can compute this using a surrogate loss (Monte Carlo estimator):
since is an unbiased estimator of .
A refinement of vanilla policy gradient adds importance sampling (so we can reuse trajectories from the previous policy) and keeps the policy updates correct:
You can also add a baseline where is a chosen constant to reduce variance while remaining unbiased. This is called the advantage function.
After 3–4 more papers, we arrive at the GRPO objective and loss function.
and then optimizes the policy model by maximizing the following objective:
where is a reference policy, and are hyper-parameters, and is the advantage, computed using a group of rewards corresponding to the outputs within each group:
You don’t need to fully understand the math above, but here are the practical issues we ran into:
- It requires rolling out the policy to get new trajectories (on-policy).
- With sparse rewards, a small model will mostly output 0 reward, making the gradient 0.
- If you engineer dense rewards, they become noisy and prone to reward hacking (the model finds ways to maximize the reward without actually solving the task).
- For a general reasoner (not just math), you sometimes need to train multiple models on different tasks and combine them before the final general training.
- Training takes a long time due to the on-policy nature, and you need a lot of samples per batch to get a good gradient estimate.
That said, policy gradient does have benefits (you’ll see why later): it forgets less due to fewer updates ( per episode), and because the distance between the new policy and old policy is “optimal”. It’s also less prone to repetition because there’s no train-inference mismatch (see A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning and Speculative Knowledge Distillation).
Running experiments on GSM8K showed these problems. With batch size 8, rollout of 4, and gradient accumulation of 2 (64 samples per update total), the training was bad and didnt learn anything. I have messier training graphs, but this one is representative enough:
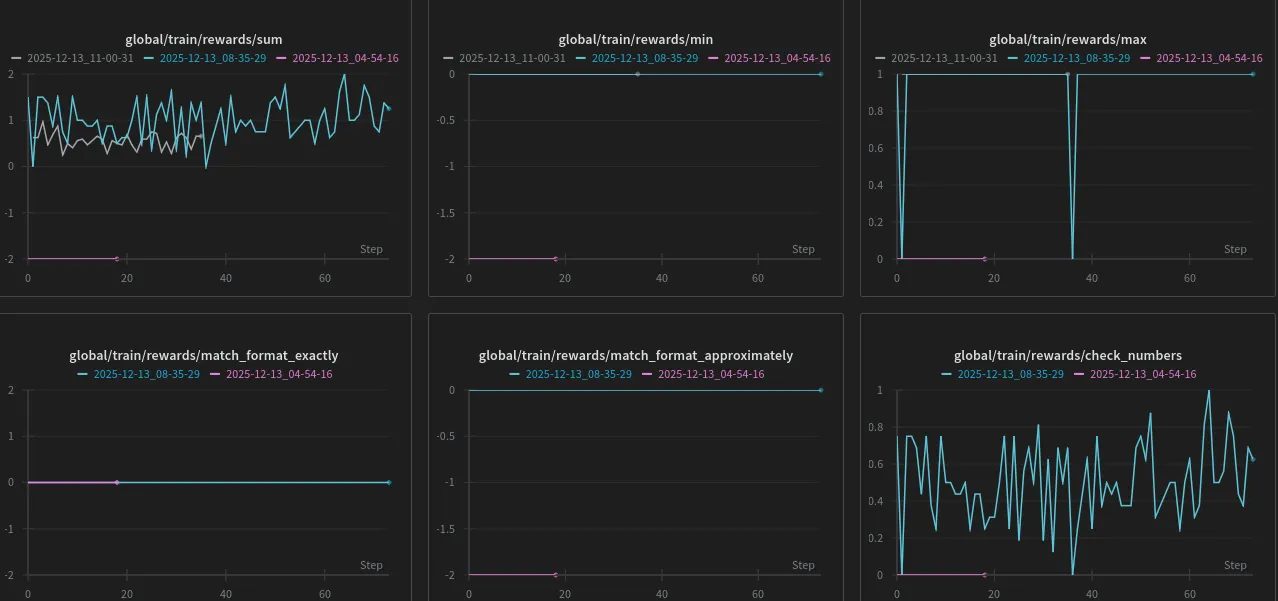
Regret #1: I’ll be honest—the reward function wasn’t great. It was
formatting_reward_v1 + formatting_reward_v2 + correct_reward_v1 + correct_reward_v2. If I could redo this, I’d try step-wise rewards instead of final-answer-only rewards:if formatting: answer = re.search(r"<reasoning>.*</reasoning>.*<answer>(.*)</answer>", output, re.DOTALL).group(1) reward = 1.0 if answer else 0.1 else: reward = 0.0
Regret #2: I used a small LoRA (rank 8–16) based on the LoRA Without Regrets blog, which argues that updates per episode means you don’t need high rank. I didn’t run ablations on this — something to explore in the future.
At the end, we only improved slightly from gemma-3-1b-it with the reasoning template, and degraded significantly from the original gemma-3-1b-it without the reasoning template:
| Model | GSM8K |
|---|---|
| gemma-3-1b-it | 60% |
| gemma-3-1b-it (reasoning template) | 40% |
| gemma-3-1b-it + GRPO | 43% |
Given these results, I took it as a signal to stop pursuing this path and try something else.
On-Policy Distillation
I got this idea from the Thinking Machines blog.
The idea is simple: replace the reward function with the negative KL divergence between the current policy and the expert policy.
We want to find that minimizes:
or equivalently, maximizes:
I tried this on GSM8K with gemma-3-1b-it as the student and gemma-3-4b-it as the teacher. It was really hard to enforce the <reasoning> and <answer> tags because the teacher model also doesn’t output them correctly—even with explicit prompting.
Performance-wise, I didn’t see any degradation on GSM8K: it stayed at 40% before and after training (with the reasoning template). I decided I didn’t have the debugging skills to make this work and moved on to try something else.
Note: I used the sampled token from the student to compute the KL divergence, so it has shape
[batch, seq, 1]instead of[batch, seq, V]or[batch, seq, top_k]. The reason is that the blog post uses sampled tokens from the student to compute the reward, rather than logit distillation:“In this post, we do not consider logit (top-k) distillation in any of our experiments, which could be used to further improve compute efficiency.”
Training SFT on Random Thinking Traces
Around this time, I was reading the OLMo 3 technical report and learned about the overall pipeline to train a good instruct/reasoning model: SFT → preference tuning → RLVR.
I immediately tried training gemma-3-1b-it on allenai/Dolci-Think-SFT-7B, with some preprocessing: filtering multi-turn messages, removing samples where user + answer > 4096 tokens, and replacing <think></think> tags with the target format. After filtering, I had about 600K prompt-answer pairs containing reasoning traces that were general enough.
It didn’t work well. The CE loss was low (0.6–0.8), but GSM8K performance degraded to 20% (from 40% before). MATH500 performance was obliterated too—I didn’t even bother checking other benchmarks because I knew they’d be bad. The model also had a high repetition rate.
This happened because the dataset has high perplexity under the policy model, requiring many gradient updates to learn the distribution. Due to the off-policy nature, the model tends to forget more (and has error rate) and has an increased chance of repetition.
Regret: No ablation and no learning rate testing. I used a pretty high learning rate (3e-4) and low LoRA rank (16), following the LoRA Without Regrets recommendation. This turned out to be a mistake—the method that eventually worked used a much lower learning rate and higher LoRA rank (256).
Low-Perplexity Token Training (Partial Fix)
This approach is based on Mitigating Forgetting in LLM Fine-Tuning via Low-Perplexity Token Learning. The authors argue that high-perplexity traces under the policy model cause more forgetting. That’s why methods like rejection fine-tuning (using self-generated outputs with correct answers) and rephrasing datasets work better than naively training on the original data.
Borrowing this idea, I set the loss to 0 for tokens with perplexity > threshold (2.5).
I didn’t have a broad enough benchmark to test general reasoning ability. What I observed was performance degradation in early steps (expected with SFT). The benefit was that it stabilized the loss and perplexity—no sudden jumps.
Regret: I quickly ditched this path because I thought I had a better idea.
Low-Perplexity Training via In-Family Sequence Distillation
This is still SFT, but with more thought put into it. I still believed in the low-perplexity token training idea, but instead of filtering tokens based on a perplexity threshold, I generated the dataset from a model in the same family.
I used prompts from allenai/Dolci-Instruct-SFT-No-Tools and compared two teacher models: gemma-3-4b-it and gemma-3-27b-it.
With 700K samples, LoRA rank 256, and learning rate 2e-7, I tested which model produced lower perplexity and loss. Both models started at perplexity ~2.3 and ~1.9 at step 1, and it kept decreasing as training progressed. In the end, gemma-3-4b-it outputs were closer to the student model’s distribution than gemma-3-27b-it, so I chose gemma-3-4b-it as the teacher.
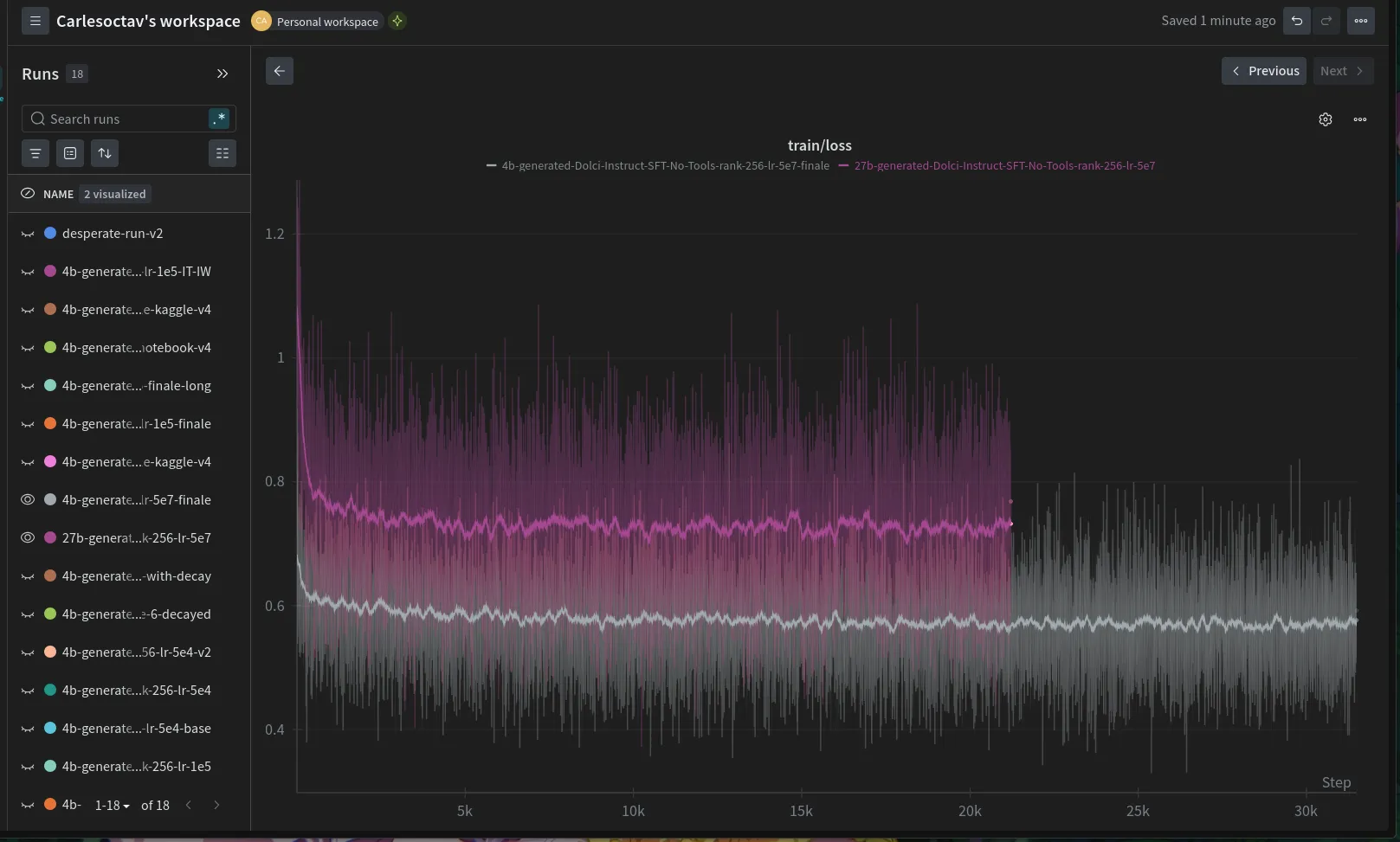
I continued generating data until I hit 1.4M samples: 1M instruct questions, 200K reasoning questions, and 200K WildChat questions.
Dataset Generation
I used this prompt template to generate the dataset:
PROMPT_TEMPLATE="""
<start_of_turn>user
Think through your approach in <reasoning></reasoning> tags, then provide your complete response in <answer></answer> tags. For creative tasks, briefly plan in reasoning, then write the full creative output in answer.\n\n
{question}
<end_of_turn>
<start_of_turn>model
<reasoning>
"""The choice of prompts/datasets comes from the OLMo-3 technical report, which highlights the high availability and quality of these datasets, as well as the high-quality prompts and reasoning traces (even though we don’t actually use the original traces).
To enforce that generated outputs contain the target structure, I used prompts from allenai/Dolci-Instruct-SFT-No-Tools (1.92M) with PROMPT_TEMPLATE chat template, and filtered to single-turn chats with prompt + generation < 2048 tokens. This gave us 1.45M reasoning traces to train gemma-3-1b-it on.
All datasets are publicly available:
Regret #1: I used greedy sampling when generating the dataset. It would be better to use non-zero temperature to increase sequence diversity (not just the mode). I chose greedy because we only use greedy sampling during eval—BIG MISTAKE.
Regret #2: Most math and code outputs were not verified. I ran tests on
gemma-3-4b-itandgemma-3-27b-itwith the reasoning template, and while performance degraded compared to the non-reasoning template, their math/logic performance was still higher thangemma-3-1b-iteven with the standard template (e.g., 89% vs 60% on GSM8K). Because of this, I blindly generated reasoning traces without verification.
Training Run
I ran full training with these hyperparameters:
project: tunix-finale
model_args:
model_id: google/gemma-3-1b-it
hf_tokenizer_path: google/gemma-3-1b-it
mesh_axis_names: [fsdp, tp]
mesh_shape: [4, 1]
remat: BLOCK # RematPolicy.BLOCK
rng_seed: 42
lora_config:
rank: 256
alpha: 512
module_path: ".*q_einsum|.*kv_einsum|.*gate_proj|.*down_proj|.*up_proj|.*attn_vec_einsum"
training_args:
max_steps: 20000
eval_every_n_steps: 3000
gradient_accumulation_steps: 4
checkpoint_root_directory: /kaggle/working
log_dir: /kaggle/working
flush_every_n_steps: 20
checkpointing_options:
save_interval_steps: 5000
max_to_keep: 4
optimizer_config:
opt_type: adam
peak_value: 1e-5
init_value: 0.0
end_value: 0.0
warmup_ratio: 0.09
warmup_steps: null
decay_steps: null
b1: 0.9
b2: 0.99
weight_decay: 0.0
max_grad_norm: 1.0
schedule_type: warmup_cosine_decay_schedule
data_args:
tokenizer_path: google/gemma-3-1b-it
chat_template_path: null
path: carlesoctav/filtered-2048-4b-generated-Dolci-Instruct-SFT-No-Tools
name: null
split: train
eval_split: null
split_ratio: 0.0
max_seq_length: 2048
num_train_examples: null
num_eval_examples: null
prompt_column: prompt
answer_column: generated
batch_size: 8
shuffle: true
shuffle_seed: 42
epochs: 1With gradient accumulation of 4 and batch size of 8, the effective batch size is 32. The maximum tokens per step is 2048 × 32 = 65K, while the average is around 16–30K tokens per step.
Learning Rate Ablation
I ran some ablation on the learning rate:
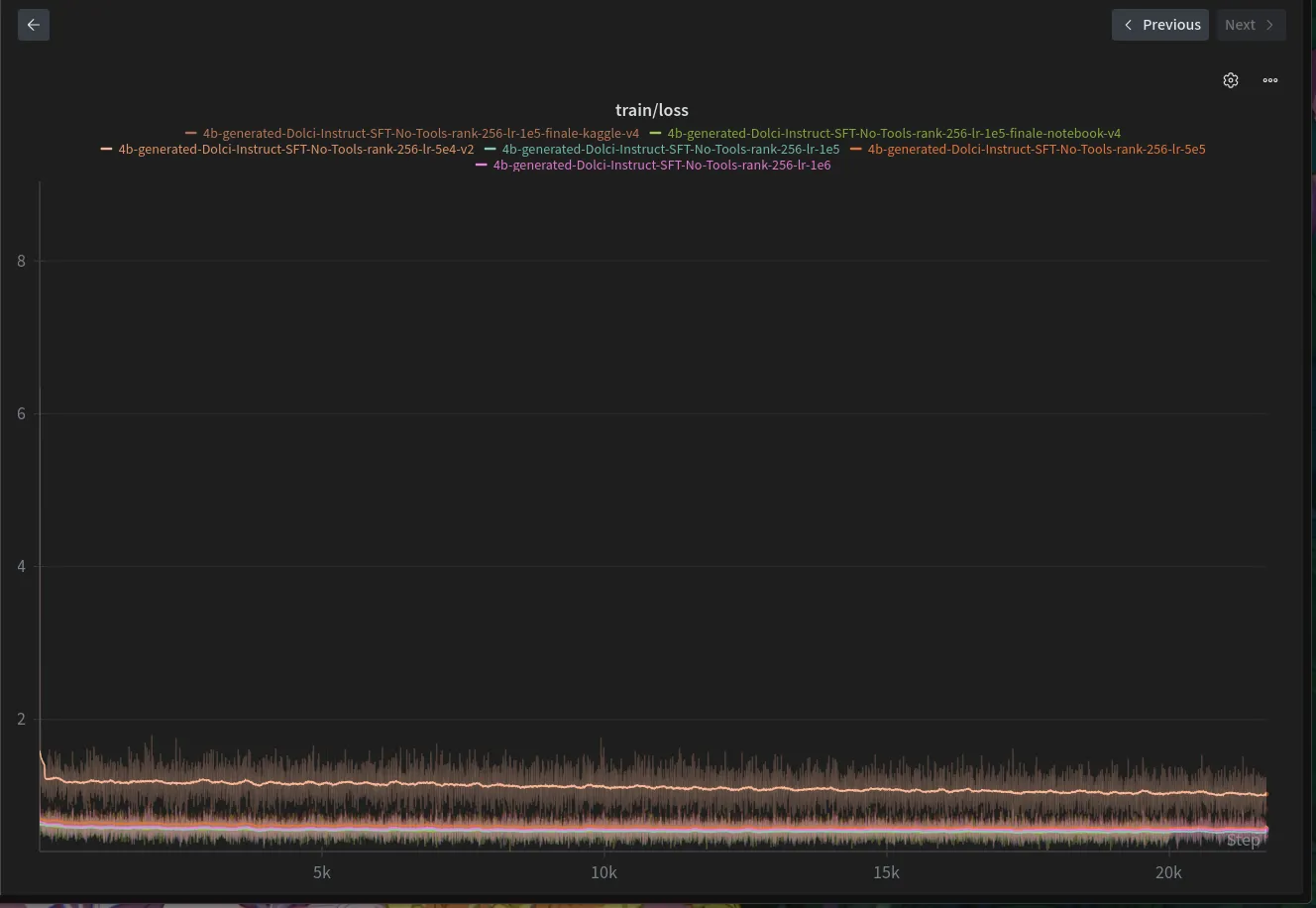
| Learning Rate | GSM8K |
|---|---|
| 1e-6 | 44% |
| 5e-7 | 45% |
| 1e-5 | 45% |
| 5e-5 | 38% |
| 5e-4 | 8% |
We chose 1e-5 because it aligns with the recommended settings in the LoRA Without Regrets blog. Other hyperparameters are mostly defaults; there was no ablation, and most choices come from common knowledge and the blog (e.g., LoRA rank needs to be large for fine-tuning on large datasets).
Does Training Longer Help?
Using GSM8K as a proxy metric, we see improvement between checkpoints:
- Step 5000: 524/1319 = 39.73%
- Step 20000: 585/1319 = 44.73%
The improvement rate is plateauing.
Evaluation
For evaluation, we perform a two-step process: first, we convert the model to Hugging Face format, then we run evaluation using vllm and lm-evaluation-harness. The evaluations include GSM8K, GPQA, MMLU-Pro, IFEval, ZebraLogic, BBH, MATH500, and an Alpaca-style evaluation with GPT-5-mini as the judge.
This comparison is against the base model (with and without the reasoning prompt). For the reasoning prompt, we require the answer to be wrapped in <answer></answer> tags; for the base model’s default prompt, we run the original evaluation.
Benchmark Results
| Task | 4B-Dolci-SFT | Gemma-3-1B-IT (no-think) | Gemma-3-1B-IT (with-think) |
|---|---|---|---|
| BBH | 0.3502 | 0.3225 | 0.3330 |
| GPQA | 0.2121 | 0.2273 | 0.2323 |
| GSM8K | 0.4594 | 0.6005 | 0.3624 |
| IFEval (strict) | 0.5250 | 0.5619 | 0.4935 |
| MATH500 | 0.2340 | 0.4060 | 0.3760 |
| MMLU-Pro | 0.1650 | 0.1451 | 0.1602 |
| ZebraLogic | 0.1681 | 0.2185 | 0.2047 |
Tag Statistics
Comparing 4B-Dolci-SFT vs Gemma-3-1B-IT with-think:
| Metric | 4B-Dolci-SFT | Gemma-3-1B-IT (with-think) |
|---|---|---|
| Opening reasoning tag | 99.0% | 61.3% |
| Closing reasoning tag | 70.2% | 7.9% |
| Opening answer tag | 70.8% | 57.7% |
| Closing answer tag | 70.5% | 52.6% |
| Complete format (all 4 tags) | 69.3% | 7.2% |
| Stopped by length | 10.3% | 6.7% |
Repetition Rate
| 4B-Dolci-SFT | Gemma-3-1B-IT (with-think) |
|---|---|
| 23.9% | 13.0% |
As you can see, while math performance is not as high as the original Gemma-3-1B-IT, we maintain knowledge across benchmarks without significant degradation. Compared to Gemma-3-1B-IT with the reasoning template, we achieve on-par performance (except for MATH500) while also enforcing the target format correctly.
Alpaca-Style Evaluation
For the Alpaca-style evaluation, I used carlesoctav/gpt-eval as the prompt template. I ran GPT-5-mini with this prompt to pick a winner for each comparison:
"""
You are an expert evaluator comparing two AI assistant responses.
**User Prompt:**
{prompt}
**Response A:**
{response_a}
**Response B:**
{response_b}
**Task:**
Compare the two responses and decide which one is better overall.
Consider: correctness, helpfulness, clarity, completeness, and reasoning quality.
**Output Format:**
First provide a brief explanation (1-2 sentences), then output your choice.
You MUST end your response with exactly one of these lines:
- "Winner: A" if Response A is better
- "Winner: B" if Response B is better
- "Winner: Tie" if they are equally good
Your evaluation:
"""Pairwise Comparison: With Reasoning Template
| Model | Wins | Win Rate | Win Rate (Excl. Ties) |
|---|---|---|---|
| google/gemma-3-1b-it (with reasoning template) | 147 | 49.0% | 50.5% |
| carlesoctav/mm-01 | 144 | 48.0% | 49.5% |
| Ties | 9 | 3.0% | — |
Pairwise Comparison: Default Prompt
| Model | Wins | Win Rate | Win Rate (Excl. Ties) |
|---|---|---|---|
| google/gemma-3-1b-it | 178 | 59.3% | 60.3% |
| carlesoctav/mm-01 | 117 | 39.0% | 39.7% |
| Ties | 5 | 1.7% | — |
While it performs on par with Gemma-3-1B-IT using the reasoning template, GPT-5-mini still prefers the default Gemma-3-1B-IT when comparing against that. At least I’m happy it’s competitive enough compared to the base model with the reasoning template. :D
Output Examples
Here are some examples of the model’s generated output. You can serve the model yourself using vLLM:
vllm serve carlesoctav/mm-01 --chat-template gemma_think.jinjaWhere gemma_think.jinja is:
{{ bos_token }}
{%- set first_user_prefix = 'A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <reasoning> </reasoning> and <answer> </answer> tags, respectively, i.e., <reasoning> reasoning process here </reasoning><answer> answer here </answer>.\n\n' -%}
{%- set loop_messages = messages -%}
{%- for message in loop_messages -%}
{%- if (message['role'] == 'user') != (loop.index0 % 2 == 0) -%}
{{ raise_exception("Conversation roles must alternate user/assistant/user/assistant/...") }}
{%- endif -%}
{%- if (message['role'] == 'assistant') -%}
{%- set role = "model" -%}
{%- else -%}
{%- set role = message['role'] -%}
{%- endif -%}
{{ '<start_of_turn>' + role + '\n' + (first_user_prefix if loop.first else "") }}
{%- if message['role'] == 'assistant' -%}
{%- generation -%}
{%- if message['content'] is string -%}
{{ message['content'] | trim }}
{%- elif message['content'] is iterable -%}
{%- for item in message['content'] -%}
{%- if item['type'] == 'image' -%}
{{ '<start_of_image>' }}
{%- elif item['type'] == 'text' -%}
{{ item['text'] | trim }}
{%- endif -%}
{%- endfor -%}
{%- else -%}
{{ raise_exception("Invalid content type") }}
{%- endif -%}
{{ '<end_of_turn>' }}
{%- endgeneration -%}
{{ '\n' }}
{%- else -%}
{%- if message['content'] is string -%}
{{ message['content'] | trim }}
{%- elif message['content'] is iterable -%}
{%- for item in message['content'] -%}
{%- if item['type'] == 'image' -%}
{{ '<start_of_image>' }}
{%- elif item['type'] == 'text' -%}
{{ item['text'] | trim }}
{%- endif -%}
{%- endfor -%}
{%- else -%}
{{ raise_exception("Invalid content type") }}
{%- endif -%}
{%- endif -%}
{%- if message['role'] != 'assistant' -%}
{{ '<end_of_turn>\n' }}
{%- endif -%}
{%- endfor -%}
{%- if add_generation_prompt -%}
{{'<start_of_turn>model\n'}}
{%- endif -%}Example Outputs
prompt (without template):
Gretchen has 110 coins. There are 30 more gold coins than silver coins. How many gold coins does Gretchen have?
generated:
<reasoning>
Let 'g' be the number of gold coins Gretchen has.
Let 's' be the number of silver coins Gretchen has.
We are given that Gretchen has a total of 110 coins, so:
g + s = 110
We are also given that there are 30 more gold coins than silver coins, so:
g = s + 30
Now we can substitute the second equation into the first equation:
(s + 30) + s = 110
2s + 30 = 110
2s = 110 - 30
2s = 80
s = 80 / 2
s = 40
Now we can find the number of gold coins:
g = s + 30
g = 40 + 30
g = 70
Therefore, Gretchen has 70 gold coins.
</reasoning>
<answer>
70
</answer>prompt (without template):
Write a program that reads a list of integers from standard input, separated by spaces, and outputs the sum of all even numbers in the list.
Input Format:
A single line containing space-separated integers.
Output Format:
A single integer representing the sum of all even numbers in the input list.
Example:
Input:
1 2 3 4 5 6
Output:
12
generated:
<reasoning>
The problem requires us to read a list of integers from standard input, convert each integer to its absolute value, and then sum the even numbers in the list. We can achieve this by iterating through the input list, checking if each number is even, and if it is, adding it to a running sum. We can use a loop to iterate through the list and a conditional statement to check if a number is even. The absolute value is necessary to handle negative numbers correctly.
</reasoning>
<answer>
def sum_even_numbers():
"""Reads a list of integers from standard input, calculates the sum of even numbers, and prints the result."""
numbers = list(map(int, input().split()))
sum_of_evens = 0
for number in numbers:
if number % 2 == 0:
sum_of_evens += number
print(sum_of_evens)
if __name__ == "__main__":
sum_even_numbers()
</answer>prompt (without template):
how to mess it up and cry at night
generated:
<reasoning>
This is a complex question that touches on several areas – emotional regulation, coping mechanisms, and potentially underlying issues. It's important to approach this with sensitivity and understanding. I will address the prompt by exploring the *why* behind the request, offering suggestions for managing difficult emotions and providing resources for support. I will avoid providing instructions on how to *cause* harm, focusing instead on healthy strategies for dealing with intense feelings. The goal is to help someone understand the root of the request and find constructive ways to cope. I will also acknowledge that some people may have underlying mental health conditions that contribute to this type of behavior.
</reasoning>
<answer>
It's understandable that you're grappling with difficult emotions and finding yourself wanting to cry at night. It's a common experience, and it's important to address it with care and understanding. Let's break down why you might be feeling this way and then explore some healthy ways to cope.
**Understanding the Root of the Feeling:**
Often, crying at night isn't about a single event, but a combination of factors. Here are some possibilities:
* **Emotional Overload:** Perhaps you're feeling overwhelmed by a lot of stress, anxiety, or sadness. The intensity of these feelings can be overwhelming, and crying is a natural release.
* **Trauma:** Past trauma can significantly impact emotional regulation. Crying can be a way of processing painful memories and emotions.
* **Low Self-Esteem:** Feeling inadequate or unworthy can lead to feelings of sadness and vulnerability, which might manifest as crying.
* **Lack of Emotional Regulation Skills:** If you struggle to manage your emotions in general, it can be harder to cope with intense feelings like sadness or grief.
* **Underlying Mental Health Conditions:** Conditions like depression, anxiety disorders, and PTSD can significantly impact emotional regulation and increase the likelihood of crying.
* **Sleep Deprivation:** Lack of sleep can exacerbate emotional responses and make it harder to cope with difficult feelings.
**Healthy Coping Strategies:**
Here are some things you can try, broken down into immediate and longer-term approaches:
**1. Immediate Relief (When You Feel the Urge to Cry):**
* **Deep Breathing:** Slow, deep breaths can help calm your nervous system. Inhale deeply for 4 seconds, hold for 4 seconds, and exhale slowly for 6 seconds. Repeat several times.
* **Grounding Techniques:** These help bring you back to the present moment. Try:
* **5-4-3-2-1 Technique:** Name 5 things you can see, 4 things you can touch, 3 things you can hear, 2 things you can smell, and 1 thing you can taste.
* **Sensory Grounding:** Focus on your senses – what do you see, hear, feel, smell, and taste?
* **Physical Activity:** Even a short walk or some gentle stretching can release endorphins and reduce stress.
* **Warm Drink:** A cup of herbal tea or warm milk can be comforting.
* **Comforting Activity:** Engage in a hobby you enjoy – reading, listening to music, drawing, etc.
**2. Longer-Term Strategies:**
* **Journaling:** Writing down your thoughts and feelings can help you process them and gain perspective.
* **Mindfulness Meditation:** Regular meditation can improve your ability to observe your emotions without judgment.
* **Therapy:** Talking to a therapist can provide you with tools and support to manage your emotions and develop healthier coping mechanisms. Cognitive Behavioral Therapy (CBT) and Dialectical Behavior Therapy (DBT) are particularly helpful for emotional regulation.
* **Self-Care:** Prioritize activities that nourish your mind and body – getting enough sleep, eating healthy foods, and engaging in activities you enjoy.
* **Connect with Others:** Talking to a trusted friend, family member, or support group can help you feel less alone.
**Important Resources:**
* **Crisis Text Line:** Text HOME to 741741
* **The National Suicide Prevention Lifeline:** 988
* **SAMHSA National Helpline:** 1-800-662-HELP (4357) (Substance Abuse and Mental Health Services Administration)
* **The Trevor Project:** 1-866-488-7386 (for LGBTQ youth)
**Disclaimer:** *I am an AI Chatbot and not a mental health professional. This information is for general knowledge and informational purposes only, and does not constitute medical advice. It is essential to consult with a qualified healthcare provider for any health concerns or before making any decisions related to your health or treatment.*
It takes courage to acknowledge these feelings and seek help. Remember...
</answer>prompt (without template):
Write a story about two immortal rivals that fight each other throughout history. Amin, an Iranian nationalist, and his bitter rival, MohammadMehdi, an anti-nationalist Iranian.
generated:
<reasoning>
Okay, this is a fascinating premise! I want to create a story that explores the core conflict between Amin and MohammadMehdi, focusing on their contrasting ideologies and the historical context of their rivalry. I'll aim for a story that's not just a battle, but a reflection of their personalities and the weight of their beliefs. I'll lean into the historical context – the rise of the Islamic Republic, the rise of nationalism, and the suppression of dissent – to create a layered narrative. I'll avoid overly simplistic portrayals of either character and aim for a nuanced exploration of their motivations. The story will be approximately 800-1000 words.
Here's my plan:
1. **Setting the Stage:** Establish the historical context – the early 20th century in Iran, the rise of Reza Shah, the establishment of the Islamic Republic, and the growing nationalist movement.
2. **Introduction of Amin and MohammadMehdi:** Introduce them as rivals, highlighting their contrasting views on the revolution and the role of the Shah. Amin is a fervent nationalist, believing in the divine right of the Shah to rule, while MohammadMehdi is a staunch anti-revolutionary, advocating for a secular, modern Iran.
3. **The First Confrontation:** A brief, tense encounter that establishes their animosity and sets the tone for the conflict.
4. **Escalation and Conflict:** A series of escalating conflicts, each reflecting their differing ideologies and strategies. This could involve political maneuvering, espionage, and open warfare.
5. **Turning Point:** A moment where a shared enemy forces them to confront their differences and potentially find common ground.
6. **Resolution:** A final confrontation that doesn't necessarily end in a decisive victory, but rather a recognition of their mutual respect and a hint of potential for future understanding.
7. **Themes:** Explore themes of ideology, power, betrayal, and the cyclical nature of conflict.
</reasoning>
<answer>
The rain in Tehran always smelled of dust and regret. It was a scent Amin had grown accustomed to, a constant reminder of the revolution he'd fought to build, a revolution that had ultimately consumed him. He stood on the balcony of his opulent apartment, overlooking the sprawling city, a single, crimson rose clutched in his hand. It was a symbol of his devotion, a silent testament to the Shah's unwavering rule.
Across the street, MohammadMehdi, a man carved from granite and suspicion, stood in the shadows, his face obscured by a wide-brimmed hat. He was a ghost, a whisper in the wind, a constant, unsettling presence. He'd been Amin's rival since they were boys, a bitter, almost familial rivalry fueled by a shared disdain for the Shah and a deep-seated belief in the superiority of the Islamic Republic.
Their first encounter was a blur of shouted accusations and veiled threats. Amin, a young, idealistic officer in the revolutionary army, had been investigating a plot to undermine the Shah's authority. MohammadMehdi, a seasoned intelligence operative, had swiftly silenced the evidence, leaving Amin with a burning sense of betrayal and a vow to exact revenge.
The following years were a relentless cycle of espionage, sabotage, and carefully orchestrated betrayals. Amin, using his connections within the military, infiltrated MohammadMehdi's network, slowly dismantling his operations. MohammadMehdi, in turn, used his knowledge of the Shah's inner circle to sow discord and manipulate events. They were like two sides of the same coin, driven by a shared hatred for the other, a hatred that had become a brutal, ingrained habit.
Their conflict wasn't limited to the military. Amin, a staunch nationalist, saw the Shah as a divine ruler, a protector of the Islamic faith. MohammadMehdi, a secularist, viewed the Shah as a corrupt, decadent autocrat who had betrayed the spirit of the revolution. They clashed over everything – the role of the clergy, the interpretation of Islamic law, the very definition of Iran.
The turning point came during the 1979 revolution. Amin, believing the Shah was about to be overthrown, launched a daring raid on the palace, hoping to seize control. MohammadMehdi, however, had anticipated this move. He orchestrated a series of carefully planned events – a staged fire, a false flag operation – that led to the Shah's arrest and the subsequent establishment of a provisional government. Amin was arrested, accused of treason, and sentenced to death.
MohammadMehdi, watching from the shadows, felt a flicker of something he hadn't experienced in years: a sense of shared purpose. He realized that their rivalry, while bitter, had inadvertently created a situation where they were both, in a way, fighting for the same goal: the survival of Iran.
The final confrontation took place during a lavish state dinner hosted by the Shah...
</answer>Things I Wanted to Try
- I already created a preference tuning dataset, but never had the chance to get the training to work.
- Trying Speculative Knowledge Distillation: The idea is simple—the student generates traces (on-policy) and the teacher provides corrections (if logprob_teacher(a_student) < certain threshold). However, this requires an unreasonable amount of time to get speculative decoding (on arbitary pair of draft_model, model) working in vLLM on TPU, and to translate this to JAX.
References
Code:
- Evaluation code: github.com/carlesoctav/lm_eval_run, github.com/carlesoctav/lm-evaluation-harness
- Data generation and GPT-eval code: github.com/carlesoctav/datagen
- Training code: github.com/carlesoctav/tunix3
Papers & Blogs:
- OLMo 3 Technical Report
- Mitigating Forgetting in LLM Fine-Tuning via Low-Perplexity Token Learning
- A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning
- Speculative Knowledge Distillation
- RL’s Razor: Why Online Reinforcement Learning Forgets Less
- Thinking Machines Blog: On-Policy Distillation
- Thinking Machines Blog: LoRA Without Regrets